DeepVis
Meet your Deep Visual Research Assistant
Directed multimodal preprocessing for document understanding beyond text extraction — how ZotGPT turns your PDFs, slides, and readings into a visually-aware knowledge base that sees everything on the page.
How It Works — For Everyone
Most AI document tools only read text. If your file has images, charts, diagrams, or handwriting, they miss it entirely. DeepVis works differently. Here is exactly what happens when you upload a file.
- 1
Step 1
You upload your file and tell the system what to look for
When you upload a document, you give DeepVis a simple instruction — for example: "Summarize any artworks shown, including colors and patterns" or "Extract any policy statements and tables." This tells the system what matters to you before it starts reading.
- 2
Step 2
DeepVis reads every page the way a human would
Instead of scanning for words like traditional tools, DeepVis looks at each page as an image. It sees the text, but it also sees pictures, diagrams, color patterns, spatial layouts, and handwriting — everything on the page. A traditional OCR-based system would skip all of that.
- 3
Step 3
For each page, the system writes a smart analysis of what it saw
Based on your instructions from Step 1, DeepVis creates a detailed note for every single page — capturing what was written, what was shown visually, how things were arranged, and any other details you asked it to focus on. Each note is tagged with its exact page number.
- 4
Step 4
All the page notes are stored in order
The notes are saved in the same order as your document — page 1, page 2, page 3, and so on. This matters because it means the system always knows where information came from and can give you an exact page number when you ask a question.
- 5
Step 5
When you ask a question, DeepVis reads through all the notes in order and answers
Your question is sent to an AI that reads through every page note from start to finish — like a research assistant who has already read the whole document for you. It answers based on what it actually found, and it tells you exactly which page the answer came from so you can verify it yourself.
Why does this matter?
Text extraction systems (often referred to as RAG) treat your document like a bag of words. They cut the text into random chunks, cannot analyze images beyond extracting text, and lose the page structure and order — such that they wrongly guess page numbers a majority of the time (93% in our testing).
DeepVis cited the correct page for every single query in testing. And when the answer lived in an image rather than text — something a text extraction system simply cannot do — DeepVis answered correctly 80% of the time. Text extraction scored 0%.
The short version: DeepVis reads your documents the way you would, remembers everything in order, and tells you exactly where it found the answer.
Key Results
DeepVis evaluated against Azure Cognitive Search RAG on a 612-page multimodal art history corpus — 15 queries across three stratified categories.
| Metric | DeepVis | RAG Baseline |
|---|---|---|
| Query Success Rate | 67% | 40% |
| Page Citation Precision | 62.5% | 1.2% |
| Page Citation Recall | 100% | 6.7% |
| Visual Content Accuracy | 80% | 0% |
Note: Both of RAG's correct visual responses were derived from co-located text, not from visual analysis of image content.
System Overview
DeepVis operates in two stages: preprocessing at upload time, and inference at query time.
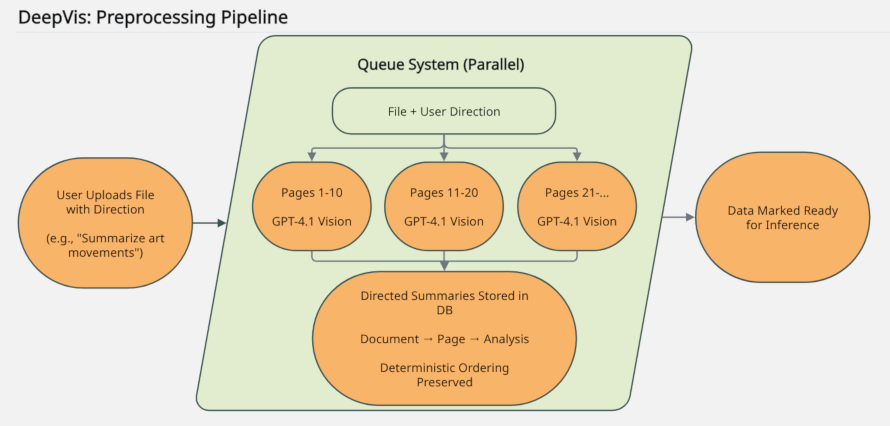
Preprocessing Pipeline
When you upload a file with a direction prompt, DeepVis processes every page in parallel using a vision-capable AI. Each page is analyzed for both text and visual content, and the results are stored as directed analyses ready for the next stage.
- → You provide a direction prompt
- → Pages processed in parallel by vision LLM
- → Directed analyses and extractions stored in document order
View Figure 1 — Preprocessing Pipeline
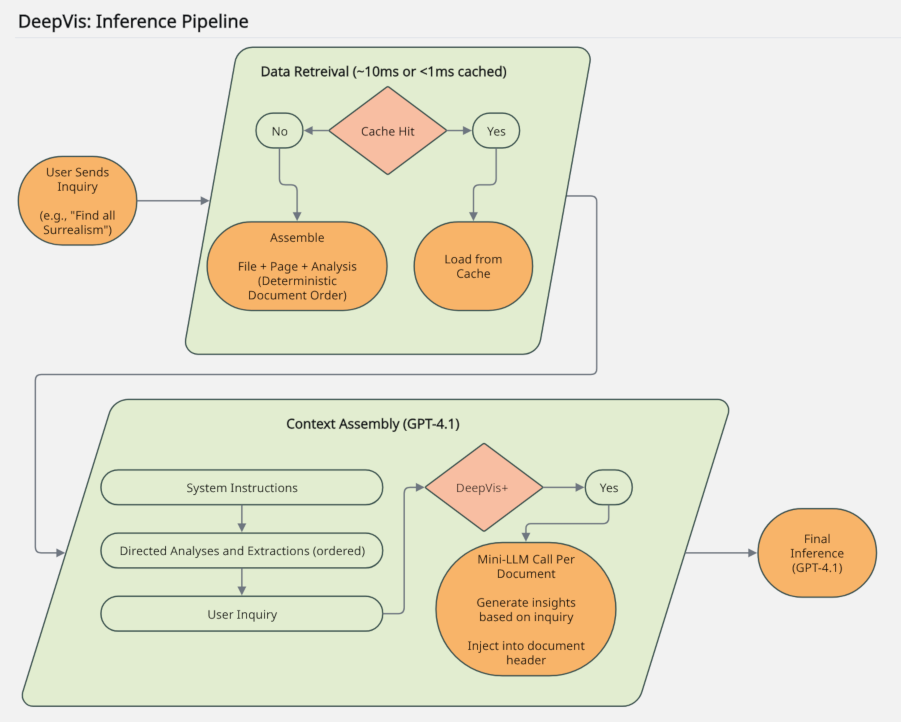
Inference Pipeline
When a user asks a question, the stored analyses are assembled in strict document order and passed — along with system instructions and the user's question — to the final AI for a grounded, citable response.
- → Analyses retrieved and assembled in document order
- → Full context passed to final LLM
- → Answer returned with exact page citations
View Figure 2 — Inference Pipeline
Deployment at UCI
DeepVis was piloted in Dean Tyrus Miller's graduate Visual Studies 295 seminar at UC Irvine from September through November 2024 using thousands of pages of art history material. Following pilot feedback, the system was refined and deployed university-wide through ClassChat, UCI's ZotGPT classroom tool. It has since expanded to Creator, UCI's ZotGPT agentic assistant tool, via administrative assistants and public-facing chatbots across UCI.
ClassChat Story
UCI OIT · January 2025
Technical Paper
DeepVis: Directed Multimodal Preprocessing for Document Understanding Beyond Text Extraction
Christopher Robert Price — AI Architect and Lead AI Developer, Office of Information Technology, University of California, Irvine
![]() 0000-0003-0015-3325
0000-0003-0015-3325
Abstract
Research across visually-rich document collections demands multimodal understanding that text-centric retrieval systems cannot provide. Retrieval-Augmented Generation (RAG) relies on OCR-based text extraction, discarding visual and spatial information critical for disciplines such as art history, while semantic chunking produces non-deterministic, fragmented context that obscures page-level structure and increases hallucination risk. We present DeepVis, a two-stage multimedia processing pipeline addressing these limitations through vision-based preprocessing, deterministic context organization, and exact page citation. Vision-capable LLMs preprocess documents page-by-page into directed artifacts organized in strict document order, preserving textual, visual, and spatial information as coherent, reproducible memory.
We evaluate DeepVis against Azure Cognitive Search RAG on Owen Jones's The Grammar of Ornament, a 612-page multimodal corpus of hand-lithographed ornamental plates, using 15 queries across three stratified categories. DeepVis achieved 100% Page Citation Recall versus RAG's 6.7% and 80% Visual Content Accuracy versus RAG's 0%; nominally correct RAG visual responses were derived from co-located text, confirming the absence of visual reasoning capability. Query success rate was 67% versus 40%, with failures attributable to static preprocessing. Deployed university-wide following pilot testing, DeepVis has expanded to administrative and public-facing applications, demonstrating that directed multimodal preprocessing enables document understanding that text-centric retrieval architectures fundamentally cannot support.
Index Terms: Multimodal Document Understanding, Vision-Language Models, Multimedia Information Retrieval, Document Image Analysis, Directed Multimodal Comprehension
This work has been submitted for possible publication. Copyright may be transferred without notice, after which this version may no longer be accessible.
View published version
Available upon publication
View Preprint
Download PDF
Cite This Work
@unpublished{price2026deepvis,
author = {Christopher Robert Price},
title = {{DeepVis}: Directed Multimodal Preprocessing for
Document Understanding Beyond Text Extraction},
note = {Submitted for publication review, March 2026.
Preprint available at University of California, Irvine},
month = {mar},
year = {2026},
url = {https://zotgpt.uci.edu/services/deepvis}
}Update volume, number, pages, and doi fields upon publication.
About the Author
Christopher Robert Price is an AI Architect and Lead AI Developer at the University of California, Irvine, Office of Information Technology. He specializes in software application architecture and AI systems development, with a research focus on the design and practical deployment of novel software solutions at the intersection of emerging technology and unexplored problem spaces. His research interests include multimodal document understanding, vision-language systems, and computer security. He holds degrees in Computer Science and Japanese, and has extensive experience building enterprise software systems including the ZotGPT platform.
Ready to put DeepVis to work?
Use DeepVis through ClassChat to power your course materials, or through Creator to build knowledge-rich assistants.